Writing code is a very creative endeavour. However, if you’re not careful, you may well end up wasting a lot of time writing code that you don’t have to.
If you haven’t spent much time writing any technical documentation, or if you’ve never been a technical writer, you might think that technical writers wouldn’t write a lot of code.
However, at least in my experience, nothing could be further from the truth.
There’s example code (in Curl, Java, PHP, Python, Ruby, and Kotlin) that demonstrates how to interact with an API.
There’s code to automate common tasks, such as validating content, simplifying finding content.
There’s code to test out different things.
It’s all part of the job.
And like writing code as a full-time occupation, at times it’s easy to get lost in the code; to forget about what you actually need to achieve.
Perhaps I’m speaking only for myself here.
However, I find it easy to get lost in the minutiae of software languages and what can be achieved using them.
And that’s just part of the fun.
There is another one.
Like any other developer, I get stuck from time to time and go in search of answers and solutions.
This can be by reading man pages and online documentation, or participating in online forums — THANK YOU Stack Overflow — and chat groups.
While each of these sources of knowledge can provide the necessary answers, they can also lead you down the proverbial rabbit hole, where you emerge hours later.
Consequently, you realise that you’ve indulged your technical, creative side, and not actually focused on the task at hand.
Perhaps it’s a sign of the creative side of all developers.
Perhaps it’s just me.
But it’s something that I regularly have to watch out for.
And so it was, recently, when I wanted to scrape some information from a site.
To give some background, I needed to get the names of the apps listed on https://marketplace.owncloud.com/dateers/owncloud.
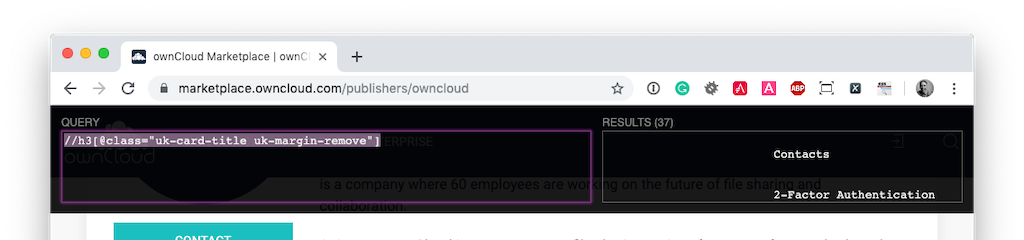
If you have a look at the DOM, you can see that the information’s listed inside the H3 tags with the uk-card-title uk-margin-remove.xh-highlight class.
Now, programmatically, how do I retrieve that information?
Well, I’ve always been a lover of XPath (and to a lesser degree, CSS Selectors).
After reviewing the XPath cheatsheet, and combined with Chrome’s XPath Helper extension, I figured that the following XPath expression //h3[@class="uk-card-title uk-margin-remove"] would retrieve the entire list of app names.
You can see in the screenshot below, that it works, almost, perfectly.
I turned to my favourite Linux command, Curl, to retrieve a copy of the page, and passed that information through to a small (bash) shell script to scrape the information.
Imagine my surprise when the script that I thought should work, didn’t.
“Why would that be”, I wondered.
Well, looking at the source of the page retrieved by Curl, the problem was obvious!
The page uses JavaScript to render the list of apps into the DOM.
As Curl isn’t JavaScript-aware, my bash script was never going work.
Want to Learn More About Mezzio?
Mezzio Essentials teaches you the fundamentals of PHP's Mezzio framework. It's a practical, hands-on approach, which shows you just enough of about the underlying
principles and concepts before stepping you through the process of creating an application.

What Was a Man to Do?
Well, it was at this juncture that I went down the wrong path (which is also the motivation for this post).
Why?
Well, I’ve been bitten (again) by the Python bug of late.
I’ve heard about Python on Command Line Heroes recently.
I’ve heard Python covered in a number of other podcasts, and talked about on a number of sites that I regularly read.
“Why not use Python”, I thought.
After all, it has a Selenium library, that I can use to handle JavaScript interaction.
So, I set to work getting everything installed and ready to go, and developing a simple script that did the job.
Here it is, just in case you’re interested.
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
executable_path = "/usr/local/Cellar/geckodriver/0.24.0/bin/geckodriver"
domain = "https://marketplace.owncloud.com/dateers/owncloud"
xpath = "//a[@type='app']"
options = webdriver.FirefoxOptions()
options.headless = True
driver = webdriver.Firefox(options=options, executable_path=executable_path)
driver.get(domain)
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH, "//div[@class='uk-first-column']")))
elements = driver.find_elements_by_xpath(xpath)
for element in elements:
print(element.find_element_by_xpath(".//div/h3").text + " / " + element.get_attribute('href'))
driver.quit()
Little did I know that I was oblivious to the fact that this Python script was completely unnecessary.
When I attempted to use it, however, it hit me like a ten-ton truck.
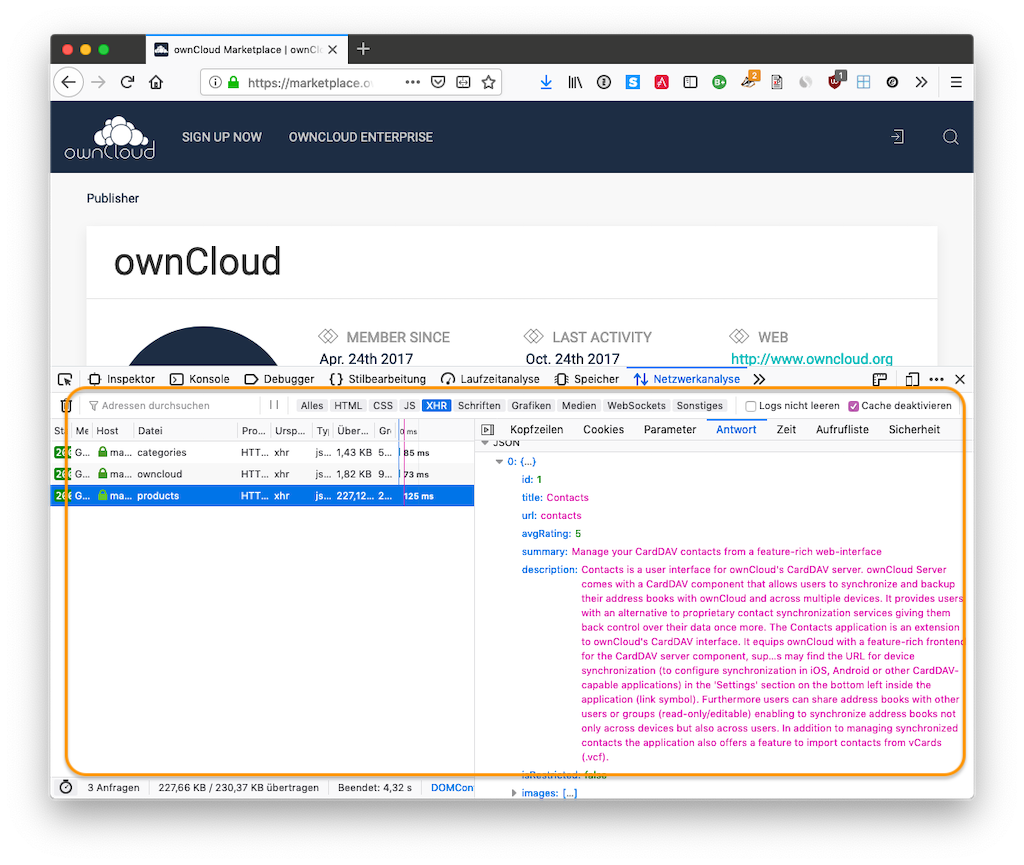
Why am I writing a Python script (or a script in any other language) when the site itself gets the information via an XHR (XMLHttpRequest)?
Why am I not just curl’ing that URL myself?
Oh the feeling of a #facepalm moment.
It’s not the first time I’ve had this experience, and I’m sure I’m not alone here.
But, despite that, I still felt a little silly for the time I’d wasted; not much, but enough.
Have a look at the code below.
It’s what I ended up using.
curl --silent --compressed \
'https://marketplace.owncloud.com/ajax/dateers/owncloud/products' \
| jq '.[].title
Rather simple, dare I say elegant, no?
The old architecture maxim below came to mind:
Less is more.
Why Am I Writing All This?
I’m writing it to put out there that while we can do things, it doesn’t that mean we always should.
I’m writing it because it’s so easy to get lost in a sense of technical and creative wonder, along with a desire to learn something new.
For these two — and many other — reasons, I believe that we should regularly give ourselves a reality check.
Yes, it’s fun to write code, to solve problems, to achieve things.
But when and how is something we should have discipline about and regularly question.
To that end, I propose the following four questions when you’re considering coding something:
- Is a technical solution necessary?
- Is the code that you’re writing necessary?
- Is there a simpler way to approach it?
- Has someone already developed something that will do the job?
Sure, if you’re doing Code Kata’s, then it’s entirely up to you what you write, because you’re meant to be creative at these times.
But outside of that, outside of when you’re just fiddling around, please keep these questions in mind.
What do you think?
Am I right?
Have I completely missed the point?





Join the discussion
comments powered by Disqus